By Daniel London
Intellectual historians may be familiar with two general approaches toward the study of conceptual meaning and transformation. The first, developed by J.G.A. Pocock and elaborated upon by Reinhart Koselleck, infers the meaning of a concept from the larger connotative framework in which it is embedded. This method entails analyzing the functional near-equivalents, competitors, and antonyms of a given term. This “internalist” approach contrasts with Quentin Skinner’s “contextualist” method, which lodges the meaning of a term in the broader intentions of that text’s author and audience. Both of these methods tend to entail close, “slow” reading of a few key texts: in a representative prelude to his conceptual history of English and American progressives, Marc Stears writes, “It is necessary… to read the texts these thinkers produced closely, carefully, and logically, to examine the complex ways in which their arguments unfolded, to see how their conceptual definitions related to one another: to employ, in short, the strategies of analytical political theory.”
But what about the seemingly antithetical approach of topic modeling? Topic modeling is, in the words of David Mimno, “a probabilistic, statistical technique that uncovers themes and topics within a text, and which can reveal patterns in otherwise unwieldy amounts of material.” In this framework, a “topic” is a probability distribution of words: a group of words that often co-occur with each other in the same set of documents. Generally, these groups of words are semantically related and interpretable; in other words, a theme, issue, or genre can often be identified simply by examining the most common words pertaining to a topic. Here is an example of a sample topic drawn from Cameron Blevins’ study of Martha Ballard’s diary, a massive corpus of 10,000 entries written between 1785 and 1812:
gardin sett worked clear beens corn warm planted matters cucumbers gatherd potatoes plants ou sowd door squash wed seeds
At first glance, this list of words might appear random and nonsensical—but here is where a contextual and humanistic reading comes into play. Statistically, these words did co-occur with one another: what could the hidden relation between them be? Blevins labeled this set “gardening.” Her next step was to chart this topic’s occurrence in Ballard’s diary over time:
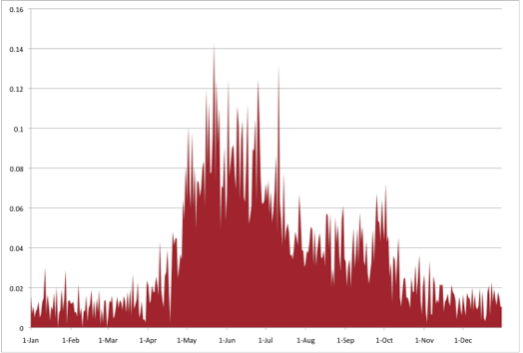
Clearly, this topic’s frequency tends to aligns with harvesting seasons. This is somewhat unsurprising, but note the significance: through mere statistical inference, a pattern of words was uncovered in a corpus far too large to be easily close-read, whose relation to one another seems to bear out both logically and in relation to real-time events.
Another topic produced by Blevins’ algorithm, which Blevins provisionally labelled “emotion,” looked like this:
feel husband unwel warm feeble felt god great fatagud fatagued thro life time year dear rose famely bu good
These two examples encapsulate the three major features of topic-modeling techniques. First, they enable us to “distantly read” a massive body of texts. Second, they reveal statistically significant distributions of words, forcing us to attend humanistically to the historical relations between them. Finally, and most importantly, these topics emerge not from our a priori assumptions and preoccupations, but from “bottom-up” algorithms. While not necessarily accurate or reflective of the actual “contents” of a given corpus—these algorithms, after all, are endlessly flexible—they are valuable, potentially counterintuitive humanistic objects of inquiry that can prompt greater understanding and generate new questions. Practitioners of topic-modeling techniques have studied coverage of runaway slaves, traced convergences and divergences in how climate change is discussed by major nonprofits, and tracked the changing contents of academic journals. They have scanned the content of entire newspapers, and charted changes in how major public issues are framed within them.
While these applications only hint at the possibilities for topic-modeling for historians in a variety of fields, a growing number of practitioners are considering the implications of this technique for historians of ideas—with results that are already surprising. Ted Underwood examined the literary journal PLMA for insights into transformations in critical theory over the twentieth century, finding that articles associated with the “structuralist” turn were appearing earlier, and were associated with different sets of concepts (“symmetry” rather than “myth” or “archetype”), than has been assumed. Michael Gavin has brilliantly compared “rights” discourse in 18,000 documents published between 1640 and 1699, detailing the frequency with which different concepts (“freedom,” “authority”) and institutions (“church,” “state”) occur within this discourse. Topic-modeling enables him to distinguish what made 1640s “rights talk” different from 1680s talk, as well as the overlap between discourses of “power” with those of “rights”:
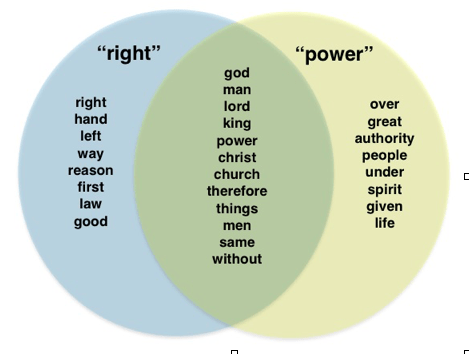
Topic-modeling does not find the “best” way to analyze text. The algorithms are malleable. It does not take word-order or emphasis into account. It does not care about motive, audience, interest, or any of those pesky “external” contexts that Skinnerians see as essential to understanding conceptual meaning. On the other hand, “internalists” will nod appreciatively at the concerns that structured Gavin’s study of “rights” discourses. Which terms co-occur when a particular keyword is invoked? Which points of connections are made between keywords? Which words and concepts appear to be central, and which are more peripheral? Which words tend to be shared across keywords, and which remain site specific? They can also agree with a more general premise behind Gavin’s study: that concepts are defined by the “distribution of the vocabulary of their contexts.” The next step is to agree that these distributions can be compared mathematically. Once you agree there, we’re in business.
Topic-modeling is, like the field of digital humanities more generally, in the phase of development which Kuhn would have called “normal science”: developing and testing methodologies that derive from established disciplinary questions and paradigms, shoring up the tool’s reliability for more adventurous work to come. For this reason, much of topic-modelers’ current work could fall into the “so-what” category. Yes, we know people gardened more in the summer, and that a king would appear frequently in the same texts as “rights” and “power.” However, conceptual historians should not be so quick to dismiss topic-modeling as a gimmick. If letting go of conceptual blinkers and generating new theories and findings is important to us, we should be willing to let go of some of our own.


April 15, 2016 at 7:13 am
Kudos! This is one of the most approachable and persuasive introductions to topic modeling that I have read. Your examples are particularly apt – it’s hard to argue with the gardening example, and the subject matter is so innocuous as to obviate the impulse for disciplinary bristling.
If you haven’t already, you might consider expanding on the “so-what” concern in the conclusion – for example, via a connection to Tom Scheinfeldt’s 2010 blog post “Where’s the Beef? Does Digital Humanities Have to Answer Questions?” (http://foundhistory.org/2010/05/wheres-the-beef-does-digital-humanities-have-to-answer-questions/). I’m particularly fond of his analogy between digital humanities and 18th century demonstrations of the electrical machine at the Royal Society: “Like 18th century natural philosophers confronted with a deluge of strange new tools like microscopes, air pumps, and electrical machines, maybe we need time to articulate our digital apparatus, to produce new phenomena that we can neither anticipate nor explain immediately.”
I am quite curious to see how this post is received. I hope there will be more replies.